
Can Search Really Scale?
or How AI Learned to Stop Worrying and Love Scaling Search

In 1959, Arthur L. Samuel wrote a research report that became cited as the first genuine work of “machine learning”. Its subject was a program that played the game of checkers, allegedly becoming a better player than its programmer.1 How did it learn to do this? Largely by trial and error, remembering what has and hasn’t worked in its experience. And how exactly did it win games? Largely by performing search, at a scale greater than what its human opponent could muster.

In the decades since Samuel’s checkers program, the threads of research on machine learning—now abbreviated ML—and machine search have separated somewhat. Most of modern machine learning uses optimization methods that are designed to incrementally improve a single solution over time rather than explore lots of possibilities in parallel. Invention in search methods is left instead to researchers in areas like reinforcement learning, a much smaller field with its own distinct lineage.2 But recent developments have made the prospect of rejoining the two very attractive.
How did search fall so far out of favor among those building AI systems? And why are they re-examining search now, all of a sudden?
Part I: Search scales, but poorly
Brute-forcing through problem mazes (for any but the most trivial problems) just won’t do. Problem-solving by this method is beyond the realm of practical possibility […] It appears that the clue to intelligent behavior […] is highly selective search, the drastic pruning of the tree of possibilities explored.
— Edward A. Feigenbaum and Julian Feldman (eds.), "Computers and Thought" (1963)
Intuitively, we might expect search to scale a certain way. Adding search should have a positive effect, in the sense that it shouldn’t lead to reduced task performance, since at worst you can always just ignore its results. Also, increased search should generally produce diminishing returns, in the sense that the size of the incremental gains should become smaller as your search becomes more comprehensive, since it is easier to improve on a bad solution than it is to improve on a decent one. These constraints point towards a general shape for the relationship between scale and performance in search: more should be better, but better should become more and more difficult.
From the earliest days of AI, the received wisdom has been that search suffers specifically from a “combinatorial explosion” or “exponential growth” in complexity.3 This is far worse than mere diminishing returns. It means that in large problem spaces, where there are many possible avenues of approach, or where solving the problem requires figuring out a whole sequence of different steps, search becomes basically unworkable.
This did not stop folks from trying. The Logic Theorist was a program developed by Allen Newell and Herbert Simon (together with programmer Cliff Shaw) that successfully synthesized several proofs of theorems from Whitehead & Russell’s Principia Mathematica. To combat the scale problem, the program picked up cues from the chosen theorem in order to limit the extent of the explosion.4 Similarly, a follow-up work of theirs called the General Problem Solver proposed to use means-end reasoning as way of restricting search to only the inferences that are potentially relevant to whatever is the current goal. These heuristics—pragmatic tricks that make search easier—were developed because it was thought they would avoid some amount of unnecessary work in the problem-solving process. But from a pessimist’s standpoint, these heuristics seemed like doomed attempts to manually hack away at the branches of an exponentially-growing tree.
Eventually the issue became undeniable. In 1973, Sir James Lighthill wrote an infamous report to the British Science Research Council in which he cited combinatorial explosion as a central obstacle to work on general-purpose AI.5 In his assessment as an outside observer, the kinds of research that would make promising investments were those that could somehow avoid the problem entirely. It is often recounted that this report caused funding for blue-sky AI research to dry up, although that story may have been an exaggeration.6
A subsequent generation of researchers hoped to build systems that could at least act as domain-specialists even if general-purpose problem solvers were too far to reach. At Stanford, Edward Feigenbaum led an effort called the Heuristic Programming Project to prove this vision out. He conjectured that the main flaw in “universal” search projects like the General Problem Solver had been that the systems lacked the right knowledge to get useful inferences off the ground, specifically the kind of knowledge that human experts possess.7 His group aimed to transfer tacit knowledge and search heuristics from human experts into machines. Early iterations of these systems like DENDRAL and MYCIN demoed well, kicking off a wave of excitement in reaction to these knowledge-based systems, or “expert systems”. But whenever they tried to translate their wins into flexible cross-domain reasoners, their efforts fizzled out before their systems could reach critical capacity.8
Part II: But search must scale
At this point in history, the only way we can obtain more intelligent machines is to design them — we cannot yet grow them, or breed them, or train them by the blind procedures that work with humans. We are caught at the wrong equilibrium of a bi-stable system: we could design more intelligent machines if we could communicate to them better; we could communicate to them better if they were more intelligent. […] At some point the reaction will “go", and we will find ourselves at the favorable equilibrium point of the system, possessing mechanisms that are both highly intelligent and communicative.
— Allen Newell, J.C. Shaw, and Herbert A. Simon, "Chess-Playing Programs and the Problem of Complexity" (1958)
Humans are an existence proof that the theoretical intractability of brute-force exploration need not be a hard barrier to search. Our brains somehow manage to navigate complex problems without constantly getting stuck. This suggests that there must be ways to make the search through problem-spaces efficient enough in general, even if we don't yet fully understand how. Researchers had a few hunches: that the right kinds of heuristics and problem frames would make search feasible. But how can we produce those in a way that is scalable and gives us confidence that they are actually helpful?
To improve how search scaled, researchers needed to break down the issue into smaller pieces that could be worked on as standalone research questions. More specifically, they needed to make progress in tandem on questions of prediction—how a problem-solver can represent a problem in ways that help it to anticipate the downstream effects of its different potential decisions—and questions of execution—how a problem-solver can make good decisions given a representation of the problem at hand. In addition to addressing these sets of questions individually, they needed a way to combine the solutions into a single package.
For questions of prediction, probabilistic models emerged as the dominant tool. Many of the discoveries here were on ways to automatically construct and update these models based on data.9 Good models allow the search process to anticipate which lines of inference are more/less likely to be productive. On the execution side, researchers turned to the theory of optimal control, working on abstractions for reasoning about decision-making problems. Rather than specifying search procedures as ad hoc collections of heuristics, they could compare entire policies: mappings from states of the problem to choices. Good policies direct the efforts of search towards the most relevant possibilities. Luckily, not only did policies and models put search on more solid footing: both could also be implemented in the same format, as neural networks.
Embracing these probabilistic and optimal control methods also meant biting a few bullets (or swallowing a few bitter pills, if you prefer). They required massive increases in investment to see continued improvements. The sheer computational resources required to make these methods work well were often beyond what was practically available at the time they were first proposed. There was a silver lining, though: the cost and performance of available compute was also improving exponentially. And as these methods were also more general than their predecessors, they could be proven out systematically.
Part III: Scaling search methods predictably
The biggest lesson that can be read from 70 years of AI research is that general methods that leverage computation are ultimately the most effective, and by a large margin. […] One thing that should be learned from the bitter lesson is the great power of general purpose methods, of methods that continue to scale with increased computation even as the available computation becomes very great.
— Richard S. Sutton, "The Bitter Lesson," personal blog (March 13, 2019)
The systematic approach worked. Building off of existing work in optimal control, new reinforcement learning (RL) algorithms were developed that came with theoretical assurances that they should converge towards the optimal policies for a given task, in the limit.10 Beyond these theoretical proofs, demonstrations like AlphaGo showed that scaling search through RL could really work in certain settings.11 The improvements in modeling technologies were even more stark, with every component of the stack (from probabilistic methods down to function approximation) witnessing rapid and impressive advances.
Results like these have led to a massive shift in mindset within AI in recent years, in large part due to the runaway success of these new systematic approaches. But the shift has not just been in choice of tools. As one researcher described it, “the driving insight of the post-2017 AI revolution was not about any particular way of ‘getting more output per unit of input.’ It was more basic than that: it was the realization that the input-output relationship exists at all.”12 As if driven by some yet-unknown law of nature, certain methods in AI seem to scale in ways that are highly predictable in the aggregate.
What is this input-output relationship for search? At the beginning of this post I outlined some general assumptions about how performance should change as a function of the scale of search. Now, with the benefit of modern methods, we can actually trace out the contours of those relationships. They tend to take the form of curves that continually increase but decelerate in the limit, as predicted. Most work so far on how neural network training scales has found that power laws (y ∝ O(x^(1/k))) fit the empirical data well across many orders of magnitude in scaling.13 Less work has been done examining trends in search methods—now reincarnated as “inference-time compute”—though it seems possible they may follow similar patterns.14 In some cases, we have evidence that the trend lines look more like variations on logarithmic relationships (y ∝ O(log(x))), where exponential resources produce linear or saturating gains, as might have been expected under traditional assumptions.1516
Given a wide enough body of knowledge and a good enough grasp of human concepts, it seems like transferring heuristics—both from humans to machines, and from one domain to another—should scale better and more predictably today. I also think that search will also “go meta”. At the moment, most RL algorithms are built to search a space of actions or physical movements. That isn’t the only level of behavioral organization, though: different problems call for different concrete actions, but the same high-level strategies generalize across them. In the future, I think more methods will search a space of thoughts or mental movements.17 And since search itself is a mental activity, it may be that scaling will involve turning the search process back in on itself.
Making scaled search effective is a challenge, but it seems like a surmountable one with promising lines of approach. It may expensive, but production of AI systems has become industrial, in the same way production of chemicals is industrial. Some of the most well-funded startups and some of the biggest technology firms on the planet are looking for recipes that scale well, now that they know that predictable scaling is possible. In light of this, it may not be wise to assume that scale will remain a bottleneck for long. It didn’t take that much for Samuel’s checkers program to outclass him, after all.
Acknowledgements go to Niccolò Zanichelli & Charles Frye for their feedback on drafts of this post, and to Algon & @datagenproc for their feedback on the power law toy model.
If you are interested in more history of artificial intelligence, I would highly recommend a book by the late Pamela McCorduck called “Machines Who Think: A Personal Inquiry into the History and Prospects of Artificial Intelligence”.
Samuel and his program make a brief appearance toward the end of a 1961 CBS television segment on “The Thinking Machine” that documented a few early AI demos. (link)
The early history of reinforcement learning has two main threads, both long and rich, that were pursued independently before intertwining in modern reinforcement learning. One thread concerns learning by trial and error, and originated in the psychology of animal learning. This thread runs through some of the earliest work in artificial intelligence and led to the revival of reinforcement learning in the early 1980s. The second thread concerns the problem of optimal control and its solution using value functions and dynamic programming.
— Richard S. Sutton and Andrew G. Barto, "Reinforcement Learning: An Introduction" (2018)
The same content appears in slightly modified form in an online version. (link)
Only two years after the term “artificial intelligence” was coined, Marvin Minsky made the following comment at the Mechanisation of Thought Processes Symposium:
The problem of exponential growth that arises in the model being considered could be regarded as a central problem of artificial intelligence—something important will be contributed when we are shown a model where
the structural tree does not grow at such a rate with the input complexity.
(link)
Allen Newell and Herbert A. Simon, "The Logic Theory Machine: A Complex Information Processing System" (1956) (link)
From the report:
These general statements are expanded in a little more detail in the rest of section 3, which has been influenced by the views of large numbers of people listed in section 1 but which like the whole of this report represents in the last analysis only the personal view of the author. Before going into such detail he is inclined, as a mathematician, to single out one rather general cause for the disappointments that have been experienced: failure to recognise the implications of the combinatorial explosion. This is a general obstacle to the construction of a self-organising system on a large knowledge base which results from the explosive growth of any combinatorial expression, representing numbers of possible ways of grouping elements of the knowledge base according to particular rules, as the base's size increases.
(link)
There was also a recorded debate surrounding the report, now available on YouTube. (link)
He specifically called out designs from the previous generation of systems built by folks like Newell, Shaw, Simon, and McCarthy, saying:
The study of generality in problem solving has been dominated by a point of view that calls for the design of "universal” methods and "universal" problem representations. These are the [General Problem Solver]-like and Advice Taker-like models. This approach to generality has great appeal, but there are difficulties intrinsic to it: the difficulty of translating specific tasks into the general representation; and the tradeoff between generality and power of the methods. […] The appropriate place for an attack on the problem of generality may be at the meta-levels of learning, knowledge transformation, and representation, not at the level of performance programs.
(link)
Likewise, he said that earlier attempts had taught how little “universal” methods matter relative to making systems knowledgeable:
We must hypothesize from our experience to date that the problem solving power exhibited in an intelligent agent’s performance is primarily a consequence of the specialist’s knowledge employed by the agent, and only very secondarily related to the generality and power of the inference method employed. Our agents must be knowledge-rich, even if they are methods-poor.
(link)
In later writings he and Doug Lenat distilled this idea into a so-called Knowledge Principle, defined as:
A system exhibits intelligent understanding and action at a high level of competence primarily because of the specific knowledge that it can bring to bear: the concepts, facts, representations, methods, models, metaphors, and heuristics about its domain of endeavor.
(link)
The most notable example of this was the Cyc project, which began in 1984 and is still underway.
Two particular procedures for this are backpropagation, which is a way of doing credit/blame assignment across structure, and Bellman updating, which is a way of doing credit/blame assignment across time.
There are many caveats. Even in the modern era, deep reinforcement learning is still only sometimes works. (link)
In addition to the blog post that is the source for the above quote (link), this researcher, nostalgebraist, has several other pieces on AI topics that I highly recommend.
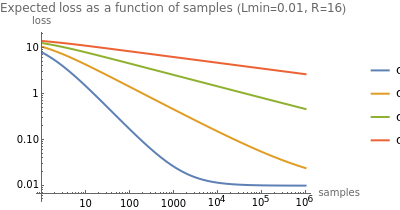
Andy Jones investigated the scaling performance of bots trained on board games, finding that the tradeoff between compute during training and inference is roughly logarithmic (link). OpenAI has indicated (link) that the performance of their o1 model on American Invitational Mathematics Examination is also a logarithmic function of test-time compute.